Estimating Equilibrium Climate Sensitivity (ECS) in CMIP6 models¶
Authors: Henry Drake and Ryan Abernathey
Adapted from https://github.com/hdrake/cmip6-temperature-demo/blob/master/notebooks/01_calculate_ECS_Gregory_method.ipynb
Definition: Equilibrium Climate Sensitivity is defined as change in global-mean near-surface air temperature (GMST) change due to an instantaneous doubling of CO\(_{2}\) concentrations and once the coupled ocean-atmosphere-sea ice system has acheived a statistical equilibrium (i.e. at the top-of-atmosphere, incoming solar shortwave radiation is balanced by reflected solar shortwave and outgoing thermal longwave radiation).
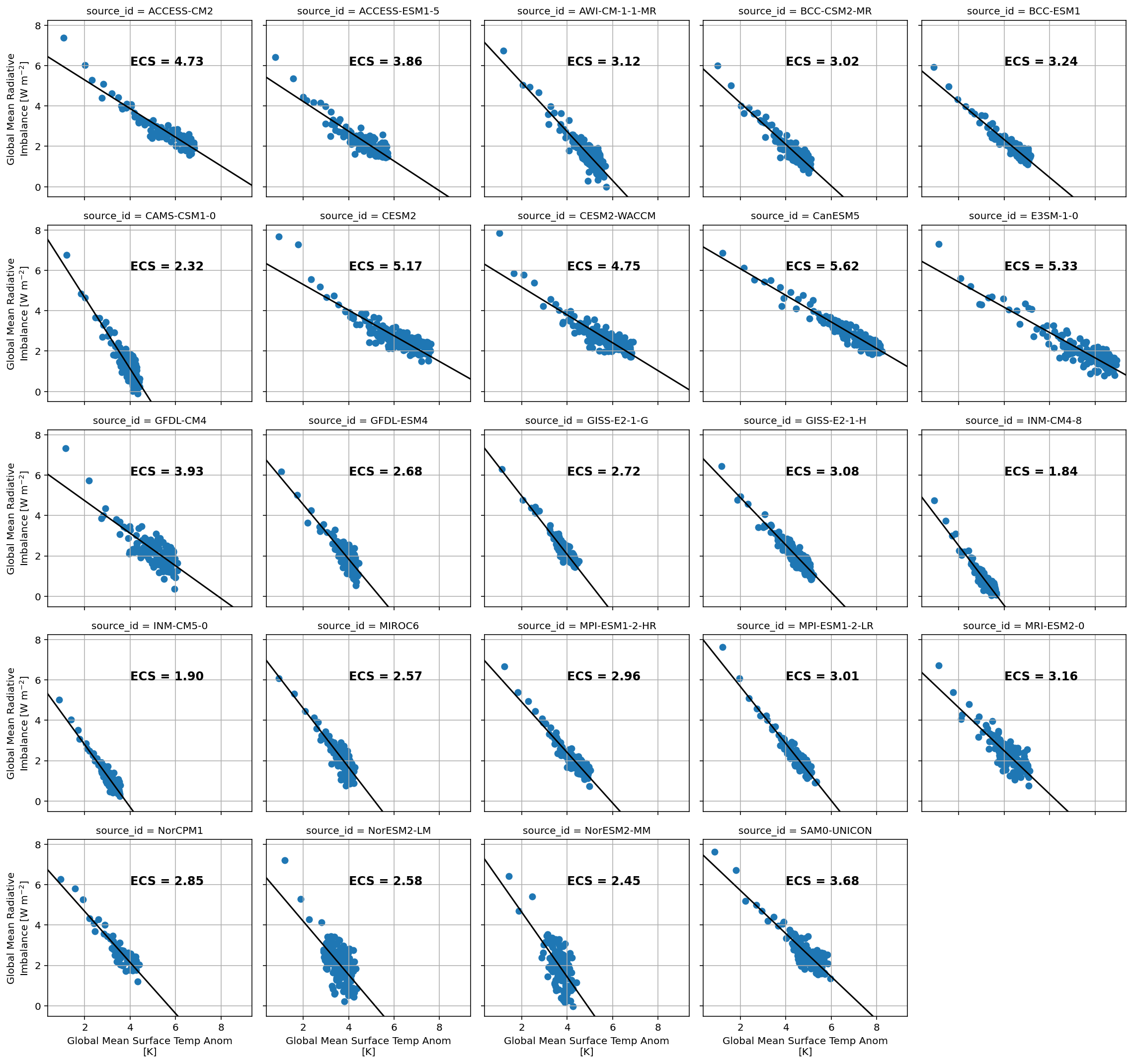
This notebook uses the “Gregory method” to approximate the ECS of CMIP6 models based on the first 150 years after an abrupt quadrupling of CO\(_{2}\) concentrations. The “Gregory Method” extrapolates the quasi-linear relationship between GMST and radiative imbalance at the top-of-atmosphere to estimate how much warming would occur if the system were in radiative balance at the top-of-atmosphere, which is by definition the equilibrium response. In particular, we extrapolate the linear relationship that occurs between 100 and 150 years after the abrupt quadrupling. Since the radiative forcing due to CO\(_{2}\) is a logarithmic function of the CO\(_{2}\) concentration, the GMST change from a first doubling is roughly the same as for a second doubling (to first order, we can assume feedbacks as constant), which means that the GMST change due to a quadrupling of CO\(_{2}\) is roughly \(\Delta T_{4 \times \text{CO}_{2}} = 2 \times \text{ECS}\). See also Mauritsen et al. 2019 for a detailed application of the Gregory Method (with modifications) for the case of one specific CMIP6 model, the MPI-M Earth System Model.
For another take on applying the Gregory method to estimate ECS, see Angeline Pendergrass’ code.
Python packages¶
[1]:
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import xarray as xr
import xesmf as xe
import cartopy
import dask
from tqdm.autonotebook import tqdm # Fancy progress bars for our loops!
import intake
import fsspec
%matplotlib inline
plt.rcParams['figure.figsize'] = 12, 6
%config InlineBackend.figure_format = 'retina'
/srv/conda/envs/notebook/lib/python3.7/site-packages/ipykernel_launcher.py:8: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)
Compute Cluster¶
Here we use a dask cluster to parallelize our analysis. The cluster scales up and down adaptively.
[2]:
from dask_gateway import Gateway
from dask.distributed import Client
gateway = Gateway()
cluster = gateway.new_cluster()
cluster.adapt(minimum=1, maximum=20)
client = Client(cluster)
cluster
Data catalogs¶
This notebook uses `intake-esm <https://intake-esm.readthedocs.io/en/latest/>`__ to ingest and organize climate model output from the fresh-off-the-supercomputers Phase 6 of the Coupled Model Intercomparison Project (CMIP6).
The file https://storage.googleapis.com/cmip6/cmip6-zarr-consolidated-stores.csv in google cloud storage contains thousands of lines of metadata, each describing an individual climate model experiment’s simulated data.
For example, the first line in the csv file contains the precipitation rate (variable_id = 'pr'), as a function of latitude, longitude, and time, in an individual climate model experiment with the BCC-ESM1 model (source_id = 'BCC-ESM1') developed by the Beijing Climate Center (institution_id = 'BCC'). The model is forced by the forcing experiment SSP370 (experiment_id = 'ssp370'), which stands for the Shared Socio-Economic Pathway 3 that results in a change in radiative forcing
of \(\Delta F = 7.0\) W/m\(^{2}\) from pre-industrial to 2100. This simulation was run as part of the AerChemMIP activity, which is a spin-off of the CMIP activity that focuses specifically on how aerosol chemistry affects climate.
[3]:
df = pd.read_csv('https://storage.googleapis.com/cmip6/cmip6-zarr-consolidated-stores.csv')
df.head()
/srv/conda/envs/notebook/lib/python3.7/site-packages/IPython/core/interactiveshell.py:3146: DtypeWarning: Columns (10) have mixed types.Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
[3]:
| activity_id | institution_id | source_id | experiment_id | member_id | table_id | variable_id | grid_label | zstore | dcpp_init_year | version | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AerChemMIP | AS-RCEC | TaiESM1 | histSST | r1i1p1f1 | AERmon | od550aer | gn | gs://cmip6/AerChemMIP/AS-RCEC/TaiESM1/histSST/... | NaN | 20200310 |
| 1 | AerChemMIP | BCC | BCC-ESM1 | histSST | r1i1p1f1 | AERmon | mmrbc | gn | gs://cmip6/AerChemMIP/BCC/BCC-ESM1/histSST/r1i... | NaN | 20190718 |
| 2 | AerChemMIP | BCC | BCC-ESM1 | histSST | r1i1p1f1 | AERmon | mmrdust | gn | gs://cmip6/AerChemMIP/BCC/BCC-ESM1/histSST/r1i... | NaN | 20191127 |
| 3 | AerChemMIP | BCC | BCC-ESM1 | histSST | r1i1p1f1 | AERmon | mmroa | gn | gs://cmip6/AerChemMIP/BCC/BCC-ESM1/histSST/r1i... | NaN | 20190809 |
| 4 | AerChemMIP | BCC | BCC-ESM1 | histSST | r1i1p1f1 | AERmon | mmrso4 | gn | gs://cmip6/AerChemMIP/BCC/BCC-ESM1/histSST/r1i... | NaN | 20191127 |
The file pangeo-cmip6.json describes the structure of the CMIP6 metadata and is formatted so as to be read in by the intake.open_esm_datastore method, which categorizes all of the data pointers into a tiered collection. For example, this collection contains the simulated data from 28691 individual experiments, representing 48 different models from 23 different scientific institutions. There are 190 different climate variables (e.g. sea surface temperature, sea ice concentration,
atmospheric winds, dissolved organic carbon in the ocean, etc.) available for 29 different forcing experiments.
Use Intake ESM¶
Intake-esm is a new package designed to make working with these data archives a bit simpler.
[4]:
col = intake.open_esm_datastore("https://storage.googleapis.com/cmip6/pangeo-cmip6.json")
col
/srv/conda/envs/notebook/lib/python3.7/site-packages/IPython/core/interactiveshell.py:3417: DtypeWarning: Columns (10) have mixed types.Specify dtype option on import or set low_memory=False.
exec(code_obj, self.user_global_ns, self.user_ns)
pangeo-cmip6 catalog with 4749 dataset(s) from 294376 asset(s):
| unique | |
|---|---|
| activity_id | 15 |
| institution_id | 34 |
| source_id | 79 |
| experiment_id | 107 |
| member_id | 213 |
| table_id | 30 |
| variable_id | 392 |
| grid_label | 10 |
| zstore | 294376 |
| dcpp_init_year | 60 |
| version | 529 |
Here, we show the various forcing experiments that climate modellers ran in these simulations.
[5]:
df['experiment_id'].unique()
[5]:
array(['histSST', 'piClim-CH4', 'piClim-NTCF', 'piClim-control', 'ssp370',
'hist-1950HC', 'piClim-2xDMS', 'piClim-2xdust', 'piClim-2xfire',
'piClim-2xss', 'piClim-BC', 'piClim-HC', 'piClim-N2O', 'piClim-OC',
'piClim-SO2', 'piClim-aer', '1pctCO2-bgc', '1pctCO2-rad',
'esm-ssp585', 'hist-bgc', 'amip-4xCO2', 'amip-future4K',
'amip-m4K', 'amip-p4K', 'amip', 'abrupt-2xCO2', 'abrupt-solp4p',
'abrupt-0p5xCO2', 'amip-lwoff', 'amip-p4K-lwoff', 'aqua-4xCO2',
'abrupt-solm4p', 'aqua-control-lwoff', 'aqua-control',
'aqua-p4K-lwoff', 'aqua-p4K', '1pctCO2', 'abrupt-4xCO2',
'historical', 'piControl', 'esm-hist', 'esm-piControl', 'ssp126',
'ssp245', 'ssp585', 'esm-piControl-spinup', 'piControl-spinup',
'hist-GHG', 'hist-aer', 'hist-nat', 'hist-CO2', 'hist-sol',
'hist-stratO3', 'hist-volc', 'ssp245-GHG', 'ssp245-aer',
'ssp245-nat', 'ssp245-stratO3', 'dcppA-hindcast', 'dcppA-assim',
'dcppC-hindcast-noAgung', 'dcppC-hindcast-noElChichon',
'dcppC-hindcast-noPinatubo', 'dcppC-amv-neg', 'dcppC-amv-pos',
'dcppC-amv-ExTrop-neg', 'dcppC-amv-ExTrop-pos',
'dcppC-amv-Trop-neg', 'dcppC-amv-Trop-pos', 'dcppC-atl-control',
'dcppC-atl-pacemaker', 'dcppC-ipv-NexTrop-neg',
'dcppC-ipv-NexTrop-pos', 'dcppC-ipv-neg', 'dcppC-ipv-pos',
'dcppC-pac-control', 'dcppC-pac-pacemaker', 'faf-heat',
'faf-passiveheat', 'faf-stress', 'faf-water', 'faf-all',
'amip-hist', 'hist-resIPO', 'highresSST-present',
'highresSST-future', 'hist-1950', 'control-1950', 'land-hist',
'deforest-globe', 'esm-ssp585-ssp126Lu', 'hist-noLu', 'land-noLu',
'omip1', 'lgm', 'lig127k', 'midHolocene', 'past1000',
'piClim-4xCO2', 'piClim-anthro', 'piClim-ghg', 'piClim-histall',
'piClim-lu', 'ssp119', 'ssp434', 'ssp460', 'ssp534-over'],
dtype=object)
Analysis of Climate Model Output Data¶
Loading data¶
intake-esm enables loading data directly into an xarray.DataArray, a metadata-aware extension of numpy arrays. xarray objects leverage dask to only read data into memory as needed for any specific operation (i.e. lazy evaluation). Think of xarray Datasets as ways of conveniently organizing large arrays of floating point numbers (e.g. climate model data) on an
n-dimensional discrete grid, with important metadata such as units, variable, names, etc.
Note that data on the cloud are in zarr format, an extension of the metadata-aware format netcdf commonly used in geosciences.
intake-esm has rules for aggegating datasets; these rules are defined in the collection-specification file.
Here, we choose the piControl experiment (in which CO2 concentrations are held fixed at a pre-industrial level of ~300 ppm) and abrupt-4xCO2 experiment (in which CO2 concentrations are instantaneously quadrupled - or doubled twice - from a pre-industrial controrl state). Since the radiative forcing of CO2 is roughly a logarithmic function of CO2 concentrations, the ECS is roughly independent of the initial CO2 concentration. Thus, if one doubling of CO2 results in \(ECS\) of warming,
then two doublings (or, a quadrupling) results in \(2 \times ECS\) of warming.
Ideally, we would choose the abrupt-2xCO2 forcing experiment, but more 4xCO2 data are currently avaiable in Google Cloud Storage, making for a better example.
Prepare Data¶
[6]:
query = dict(
experiment_id=['abrupt-4xCO2','piControl'], # pick the `abrupt-4xCO2` and `piControl` forcing experiments
table_id='Amon', # choose to look at atmospheric variables (A) saved at monthly resolution (mon)
variable_id=['tas', 'rsut','rsdt','rlut'], # choose to look at near-surface air temperature (tas) as our variable
member_id = 'r1i1p1f1', # arbitrarily pick one realization for each model (i.e. just one set of initial conditions)
)
col_subset = col.search(require_all_on=["source_id"], **query)
col_subset.df.groupby("source_id")[
["experiment_id", "variable_id", "table_id"]
].nunique()
[6]:
| experiment_id | variable_id | table_id | |
|---|---|---|---|
| source_id | |||
| ACCESS-CM2 | 2 | 4 | 1 |
| ACCESS-ESM1-5 | 2 | 4 | 1 |
| AWI-CM-1-1-MR | 2 | 4 | 1 |
| BCC-CSM2-MR | 2 | 4 | 1 |
| BCC-ESM1 | 2 | 4 | 1 |
| CAMS-CSM1-0 | 2 | 4 | 1 |
| CESM2 | 2 | 4 | 1 |
| CESM2-WACCM | 2 | 4 | 1 |
| CanESM5 | 2 | 4 | 1 |
| E3SM-1-0 | 2 | 4 | 1 |
| EC-Earth3-Veg | 2 | 4 | 1 |
| GFDL-CM4 | 2 | 4 | 1 |
| GFDL-ESM4 | 2 | 4 | 1 |
| GISS-E2-1-G | 2 | 4 | 1 |
| GISS-E2-1-H | 2 | 4 | 1 |
| INM-CM4-8 | 2 | 4 | 1 |
| INM-CM5-0 | 2 | 4 | 1 |
| IPSL-CM6A-LR | 2 | 4 | 1 |
| KACE-1-0-G | 2 | 4 | 1 |
| MIROC6 | 2 | 4 | 1 |
| MPI-ESM1-2-HR | 2 | 4 | 1 |
| MPI-ESM1-2-LR | 2 | 4 | 1 |
| MRI-ESM2-0 | 2 | 4 | 1 |
| NESM3 | 2 | 4 | 1 |
| NorCPM1 | 2 | 4 | 1 |
| NorESM2-LM | 2 | 4 | 1 |
| NorESM2-MM | 2 | 4 | 1 |
| SAM0-UNICON | 2 | 4 | 1 |
The following functions help us load and homogenize the data. We use some dask.delayed programming to open the datasets in parallel.
[7]:
def drop_all_bounds(ds):
"""Drop coordinates like 'time_bounds' from datasets,
which can lead to issues when merging."""
drop_vars = [vname for vname in ds.coords
if (('_bounds') in vname ) or ('_bnds') in vname]
return ds.drop(drop_vars)
def open_dsets(df):
"""Open datasets from cloud storage and return xarray dataset."""
dsets = [xr.open_zarr(fsspec.get_mapper(ds_url), consolidated=True)
.pipe(drop_all_bounds)
for ds_url in df.zstore]
try:
ds = xr.merge(dsets, join='exact')
return ds
except ValueError:
return None
def open_delayed(df):
"""A dask.delayed wrapper around `open_dsets`.
Allows us to open many datasets in parallel."""
return dask.delayed(open_dsets)(df)
Create a nested dictionary of models and experiments. It will be structured like this:
{'CESM2':
{
'piControl': <xarray.Dataset>,
'abrupt-4xCO2': <xarray.Dataset>
},
...
}
[8]:
from collections import defaultdict
dsets = defaultdict(dict)
for group, df in col_subset.df.groupby(by=['source_id', 'experiment_id']):
dsets[group[0]][group[1]] = open_delayed(df)
Open one of the datasets directly, just to show what it looks like:
[9]:
%time open_dsets(df)
CPU times: user 876 ms, sys: 72.2 ms, total: 948 ms
Wall time: 1.54 s
[9]:
<xarray.Dataset>
Dimensions: (lat: 192, lon: 288, time: 8400)
Coordinates:
* lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0
* lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8
* time (time) object 0001-01-16 12:00:00 ... 0700-12-16 12:00:00
height float64 ...
Data variables:
rlut (time, lat, lon) float32 dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
rsdt (time, lat, lon) float32 dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
rsut (time, lat, lon) float32 dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
tas (time, lat, lon) float32 dask.array<chunksize=(600, 192, 288), meta=np.ndarray>- lat: 192
- lon: 288
- time: 8400
- lat(lat)float64-90.0 -89.06 -88.12 ... 89.06 90.0
- axis :
- Y
- bounds :
- lat_bnds
- long_name :
- Latitude
- standard_name :
- latitude
- units :
- degrees_north
array([-90. , -89.057592, -88.115183, -87.172775, -86.230366, -85.287958, -84.34555 , -83.403141, -82.460733, -81.518325, -80.575916, -79.633508, -78.691099, -77.748691, -76.806283, -75.863874, -74.921466, -73.979058, -73.036649, -72.094241, -71.151832, -70.209424, -69.267016, -68.324607, -67.382199, -66.439791, -65.497382, -64.554974, -63.612565, -62.670157, -61.727749, -60.78534 , -59.842932, -58.900524, -57.958115, -57.015707, -56.073298, -55.13089 , -54.188482, -53.246073, -52.303665, -51.361257, -50.418848, -49.47644 , -48.534031, -47.591623, -46.649215, -45.706806, -44.764398, -43.82199 , -42.879581, -41.937173, -40.994764, -40.052356, -39.109948, -38.167539, -37.225131, -36.282723, -35.340314, -34.397906, -33.455497, -32.513089, -31.570681, -30.628272, -29.685864, -28.743455, -27.801047, -26.858639, -25.91623 , -24.973822, -24.031414, -23.089005, -22.146597, -21.204188, -20.26178 , -19.319372, -18.376963, -17.434555, -16.492147, -15.549738, -14.60733 , -13.664921, -12.722513, -11.780105, -10.837696, -9.895288, -8.95288 , -8.010471, -7.068063, -6.125654, -5.183246, -4.240838, -3.298429, -2.356021, -1.413613, -0.471204, 0.471204, 1.413613, 2.356021, 3.298429, 4.240838, 5.183246, 6.125654, 7.068063, 8.010471, 8.95288 , 9.895288, 10.837696, 11.780105, 12.722513, 13.664921, 14.60733 , 15.549738, 16.492147, 17.434555, 18.376963, 19.319372, 20.26178 , 21.204188, 22.146597, 23.089005, 24.031414, 24.973822, 25.91623 , 26.858639, 27.801047, 28.743455, 29.685864, 30.628272, 31.570681, 32.513089, 33.455497, 34.397906, 35.340314, 36.282723, 37.225131, 38.167539, 39.109948, 40.052356, 40.994764, 41.937173, 42.879581, 43.82199 , 44.764398, 45.706806, 46.649215, 47.591623, 48.534031, 49.47644 , 50.418848, 51.361257, 52.303665, 53.246073, 54.188482, 55.13089 , 56.073298, 57.015707, 57.958115, 58.900524, 59.842932, 60.78534 , 61.727749, 62.670157, 63.612565, 64.554974, 65.497382, 66.439791, 67.382199, 68.324607, 69.267016, 70.209424, 71.151832, 72.094241, 73.036649, 73.979058, 74.921466, 75.863874, 76.806283, 77.748691, 78.691099, 79.633508, 80.575916, 81.518325, 82.460733, 83.403141, 84.34555 , 85.287958, 86.230366, 87.172775, 88.115183, 89.057592, 90. ]) - lon(lon)float640.0 1.25 2.5 ... 356.2 357.5 358.8
- axis :
- X
- bounds :
- lon_bnds
- long_name :
- Longitude
- standard_name :
- longitude
- units :
- degrees_east
array([ 0. , 1.25, 2.5 , ..., 356.25, 357.5 , 358.75])
- time(time)object0001-01-16 12:00:00 ... 0700-12-...
- axis :
- T
- bounds :
- time_bnds
- long_name :
- time
- standard_name :
- time
array([cftime.DatetimeNoLeap(1, 1, 16, 12, 0, 0, 0), cftime.DatetimeNoLeap(1, 2, 15, 0, 0, 0, 0), cftime.DatetimeNoLeap(1, 3, 16, 12, 0, 0, 0), ..., cftime.DatetimeNoLeap(700, 10, 16, 12, 0, 0, 0), cftime.DatetimeNoLeap(700, 11, 16, 0, 0, 0, 0), cftime.DatetimeNoLeap(700, 12, 16, 12, 0, 0, 0)], dtype=object) - height()float64...
- axis :
- Z
- long_name :
- height
- positive :
- up
- standard_name :
- height
- units :
- m
array(2.)
- rlut(time, lat, lon)float32dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
- cell_measures :
- area: areacella
- cell_methods :
- area: time: mean (interval: 1 month)
- comment :
- at the top of the atmosphere (to be compared with satellite measurements)
- long_name :
- TOA Outgoing Longwave Radiation
- original_units :
- W/m2
- standard_name :
- toa_outgoing_longwave_flux
- units :
- W m-2
Array Chunk Bytes 1.86 GB 132.71 MB Shape (8400, 192, 288) (600, 192, 288) Count 15 Tasks 14 Chunks Type float32 numpy.ndarray - rsdt(time, lat, lon)float32dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
- cell_measures :
- area: areacella
- cell_methods :
- area: time: mean (interval: 1 month)
- comment :
- Shortwave radiation incident at the top of the atmosphere
- long_name :
- TOA Incident Shortwave Radiation
- original_units :
- W/m2
- standard_name :
- toa_incoming_shortwave_flux
- units :
- W m-2
Array Chunk Bytes 1.86 GB 132.71 MB Shape (8400, 192, 288) (600, 192, 288) Count 15 Tasks 14 Chunks Type float32 numpy.ndarray - rsut(time, lat, lon)float32dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
- cell_measures :
- area: areacella
- cell_methods :
- area: time: mean (interval: 1 month)
- comment :
- at the top of the atmosphere
- long_name :
- TOA Outgoing Shortwave Radiation
- original_units :
- W/m2
- standard_name :
- toa_outgoing_shortwave_flux
- units :
- W m-2
Array Chunk Bytes 1.86 GB 132.71 MB Shape (8400, 192, 288) (600, 192, 288) Count 15 Tasks 14 Chunks Type float32 numpy.ndarray - tas(time, lat, lon)float32dask.array<chunksize=(600, 192, 288), meta=np.ndarray>
- cell_measures :
- area: areacella
- cell_methods :
- area: time: mean (interval: 1 month)
- comment :
- near-surface (usually, 2 meter) air temperature
- long_name :
- Near-Surface Air Temperature
- standard_name :
- air_temperature
- units :
- K
Array Chunk Bytes 1.86 GB 132.71 MB Shape (8400, 192, 288) (600, 192, 288) Count 15 Tasks 14 Chunks Type float32 numpy.ndarray
Now use dask to do this in parallel on all of the datasets:
[10]:
dsets_ = dask.compute(dict(dsets))[0]
Reduce Data via Global Mean¶
We don’t want to load all of the raw model data into memory right away. Instead, we want to reduce the data by taking the global mean. We need to remember to weight this global mean by a factor proportional to cos(lat).
[11]:
def get_lat_name(ds):
"""Figure out what is the latitude coordinate for each dataset."""
for lat_name in ['lat', 'latitude']:
if lat_name in ds.coords:
return lat_name
raise RuntimeError("Couldn't find a latitude coordinate")
def global_mean(ds):
"""Return global mean of a whole dataset."""
lat = ds[get_lat_name(ds)]
weight = np.cos(np.deg2rad(lat))
weight /= weight.mean()
other_dims = set(ds.dims) - {'time'}
return (ds * weight).mean(other_dims)
We now apply this function, plus resampling to annual mean data, to all of the datasets. We also concatenate the experiments together into a single Dataset for each model. This is the most complex cell in the notebook. A lot is happening here.
[12]:
expts = ['piControl', 'abrupt-4xCO2']
expt_da = xr.DataArray(expts, dims='experiment_id',
coords={'experiment_id': expts})
dsets_aligned = {}
for k, v in tqdm(dsets_.items()):
expt_dsets = v.values()
if any([d is None for d in expt_dsets]):
print(f"Missing experiment for {k}")
continue
for ds in expt_dsets:
ds.coords['year'] = ds.time.dt.year - ds.time.dt.year[0]
# workaround for
# https://github.com/pydata/xarray/issues/2237#issuecomment-620961663
dsets_ann_mean = [v[expt].pipe(global_mean)
.swap_dims({'time': 'year'})
.drop('time')
.coarsen(year=12).mean()
for expt in expts]
# align everything with the 4xCO2 experiment
dsets_aligned[k] = xr.concat(dsets_ann_mean, join='right',
dim=expt_da)
Missing experiment for EC-Earth3-Veg
Missing experiment for IPSL-CM6A-LR
Missing experiment for KACE-1-0-G
Missing experiment for NESM3
Do the Computation¶
Up to this point, no computations have actually happened. Everything has been “lazy”. Now we trigger the computation to actual occur and load the global / annual mean data into memory.
[13]:
dsets_aligned_ = dask.compute(dsets_aligned)[0]
Now we concatenate across models to produce one big dataset with all the required variables.
[14]:
source_ids = list(dsets_aligned_.keys())
source_da = xr.DataArray(source_ids, dims='source_id',
coords={'source_id': source_ids})
big_ds = xr.concat([ds.reset_coords(drop=True)
for ds in dsets_aligned_.values()],
dim=source_da)
big_ds
[14]:
<xarray.Dataset>
Dimensions: (experiment_id: 2, source_id: 24, year: 999)
Coordinates:
* source_id (source_id) object 'ACCESS-CM2' ... 'SAM0-UNICON'
* year (year) float64 0.0 1.0 2.0 3.0 ... 995.0 996.0 997.0 998.0
* experiment_id (experiment_id) object 'piControl' 'abrupt-4xCO2'
Data variables:
rlut (source_id, experiment_id, year) float64 242.2 242.0 ... nan
rsdt (source_id, experiment_id, year) float64 340.4 340.4 ... nan
rsut (source_id, experiment_id, year) float64 97.84 97.84 ... nan
tas (source_id, experiment_id, year) float64 287.0 287.0 ... nan
None (source_id) <U13 'ACCESS-CM2' ... 'SAM0-UNICON'- experiment_id: 2
- source_id: 24
- year: 999
- source_id(source_id)object'ACCESS-CM2' ... 'SAM0-UNICON'
array(['ACCESS-CM2', 'ACCESS-ESM1-5', 'AWI-CM-1-1-MR', 'BCC-CSM2-MR', 'BCC-ESM1', 'CAMS-CSM1-0', 'CESM2', 'CESM2-WACCM', 'CanESM5', 'E3SM-1-0', 'GFDL-CM4', 'GFDL-ESM4', 'GISS-E2-1-G', 'GISS-E2-1-H', 'INM-CM4-8', 'INM-CM5-0', 'MIROC6', 'MPI-ESM1-2-HR', 'MPI-ESM1-2-LR', 'MRI-ESM2-0', 'NorCPM1', 'NorESM2-LM', 'NorESM2-MM', 'SAM0-UNICON'], dtype=object) - year(year)float640.0 1.0 2.0 ... 996.0 997.0 998.0
array([ 0., 1., 2., ..., 996., 997., 998.])
- experiment_id(experiment_id)object'piControl' 'abrupt-4xCO2'
array(['piControl', 'abrupt-4xCO2'], dtype=object)
- rlut(source_id, experiment_id, year)float64242.2 242.0 242.2 ... nan nan nan
array([[[242.1531882 , 242.03535435, 242.19435088, ..., nan, nan, nan], [237.84149141, 240.37242666, 241.2120226 , ..., nan, nan, nan]], [[244.70193143, 245.31180089, 245.31419418, ..., nan, nan, nan], [240.66729217, 242.41553496, 243.44455669, ..., nan, nan, nan]], [[242.10514955, 241.81071275, 241.74838414, ..., nan, nan, nan], [236.00200597, 237.58654171, 238.08162789, ..., nan, nan, nan]], ..., [[239.27691194, 239.25672458, 238.87888775, ..., nan, nan, nan], [233.8375387 , 235.36080178, 236.23165468, ..., nan, nan, nan]], [[240.02849542, 239.75662675, 239.94289949, ..., nan, nan, nan], [234.66461065, 235.70179366, 236.66114085, ..., nan, nan, nan]], [[239.73369905, 239.78533033, 239.3032221 , ..., nan, nan, nan], [233.5199945 , 235.74675419, 237.06011175, ..., nan, nan, nan]]]) - rsdt(source_id, experiment_id, year)float64340.4 340.4 340.4 ... nan nan nan
array([[[340.36208408, 340.36208408, 340.37045763, ..., nan, nan, nan], [340.36208408, 340.36208408, 340.37045763, ..., nan, nan, nan]], [[341.59849936, 341.59849936, 341.59849936, ..., nan, nan, nan], [341.59849936, 341.59849936, 341.59849936, ..., nan, nan, nan]], [[340.26383893, 340.26383893, 340.26383893, ..., nan, nan, nan], [340.26383917, 340.26383893, 340.2574068 , ..., nan, nan, nan]], ..., [[340.26584615, 340.26584635, 340.26584646, ..., nan, nan, nan], [340.26583083, 340.2658323 , 340.2658333 , ..., nan, nan, nan]], [[340.25477473, 340.25477445, 340.25477458, ..., nan, nan, nan], [340.25476 , 340.25476103, 340.25476148, ..., nan, nan, nan]], [[340.25594501, 340.25594503, 340.25594503, ..., nan, nan, nan], [340.25594501, 340.25594503, 340.25594503, ..., nan, nan, nan]]]) - rsut(source_id, experiment_id, year)float6497.84 97.84 97.72 ... nan nan nan
array([[[ 97.83618435, 97.83881778, 97.72420607, ..., nan, nan, nan], [ 94.71758801, 93.55442598, 93.46030249, ..., nan, nan, nan]], [[ 96.73544491, 96.28390485, 96.61879237, ..., nan, nan, nan], [ 94.69104059, 94.0132486 , 93.90088584, ..., nan, nan, nan]], [[ 98.22844114, 98.12306031, 97.72634609, ..., nan, nan, nan], [ 97.2014341 , 97.31936045, 96.9286617 , ..., nan, nan, nan]], ..., [[101.039549 , 100.19597308, 101.6048536 , ..., nan, nan, nan], [ 99.22303996, 99.61218088, 99.75613562, ..., nan, nan, nan]], [[100.92003295, 100.52852514, 100.87136099, ..., nan, nan, nan], [ 99.18287695, 99.88372907, 98.21472195, ..., nan, nan, nan]], [[ 99.09339986, 99.23626883, 99.00812923, ..., nan, nan, nan], [ 97.31173828, 95.99819253, 96.20814592, ..., nan, nan, nan]]]) - tas(source_id, experiment_id, year)float64287.0 287.0 287.1 ... nan nan nan
array([[[286.97130316, 287.01273733, 287.05322668, ..., nan, nan, nan], [288.08007778, 289.02285565, 289.33196392, ..., nan, nan, nan]], [[287.4538212 , 287.59293088, 287.66311038, ..., nan, nan, nan], [288.39745905, 289.16965483, 289.61736708, ..., nan, nan, nan]], [[287.07562685, 286.97408795, 286.84901823, ..., nan, nan, nan], [288.11374992, 288.97867377, 289.27620022, ..., nan, nan, nan]], ..., [[287.5837734 , 287.67998514, 287.69868085, ..., nan, nan, nan], [288.79615142, 289.50799917, 289.87106781, ..., nan, nan, nan]], [[287.09501341, 287.05798871, 287.02848481, ..., nan, nan, nan], [288.34825901, 288.7888122 , 289.38198728, ..., nan, nan, nan]], [[286.44398785, 286.45580714, 286.35515818, ..., nan, nan, nan], [287.16584815, 288.11511453, 288.53517771, ..., nan, nan, nan]]]) - None(source_id)<U13'ACCESS-CM2' ... 'SAM0-UNICON'
array(['ACCESS-CM2', 'ACCESS-ESM1-5', 'AWI-CM-1-1-MR', 'BCC-CSM2-MR', 'BCC-ESM1', 'CAMS-CSM1-0', 'CESM2', 'CESM2-WACCM', 'CanESM5', 'E3SM-1-0', 'GFDL-CM4', 'GFDL-ESM4', 'GISS-E2-1-G', 'GISS-E2-1-H', 'INM-CM4-8', 'INM-CM5-0', 'MIROC6', 'MPI-ESM1-2-HR', 'MPI-ESM1-2-LR', 'MRI-ESM2-0', 'NorCPM1', 'NorESM2-LM', 'NorESM2-MM', 'SAM0-UNICON'], dtype='<U13')
Calculated Derived Variables¶
We need to calculate the net radiative imbalance, plus the anomaly of the abrupt 4xCO2 run compared to the piControl run.
[15]:
big_ds['imbalance'] = big_ds['rsdt'] - big_ds['rsut'] - big_ds['rlut']
ds_mean = big_ds[['tas', 'imbalance']].sel(experiment_id='piControl').mean(dim='year')
ds_anom = big_ds[['tas', 'imbalance']] - ds_mean
# add some metadata
ds_anom.tas.attrs['long_name'] = 'Global Mean Surface Temp Anom'
ds_anom.tas.attrs['units'] = 'K'
ds_anom.imbalance.attrs['long_name'] = 'Global Mean Radiative Imbalance'
ds_anom.imbalance.attrs['units'] = 'W m$^{-2}$'
ds_anom
[15]:
<xarray.Dataset>
Dimensions: (experiment_id: 2, source_id: 24, year: 999)
Coordinates:
* source_id (source_id) object 'ACCESS-CM2' ... 'SAM0-UNICON'
* year (year) float64 0.0 1.0 2.0 3.0 ... 995.0 996.0 997.0 998.0
* experiment_id (experiment_id) object 'piControl' 'abrupt-4xCO2'
Data variables:
tas (source_id, experiment_id, year) float64 -0.03737 ... nan
imbalance (source_id, experiment_id, year) float64 -0.04809 ... nan- experiment_id: 2
- source_id: 24
- year: 999
- source_id(source_id)object'ACCESS-CM2' ... 'SAM0-UNICON'
array(['ACCESS-CM2', 'ACCESS-ESM1-5', 'AWI-CM-1-1-MR', 'BCC-CSM2-MR', 'BCC-ESM1', 'CAMS-CSM1-0', 'CESM2', 'CESM2-WACCM', 'CanESM5', 'E3SM-1-0', 'GFDL-CM4', 'GFDL-ESM4', 'GISS-E2-1-G', 'GISS-E2-1-H', 'INM-CM4-8', 'INM-CM5-0', 'MIROC6', 'MPI-ESM1-2-HR', 'MPI-ESM1-2-LR', 'MRI-ESM2-0', 'NorCPM1', 'NorESM2-LM', 'NorESM2-MM', 'SAM0-UNICON'], dtype=object) - year(year)float640.0 1.0 2.0 ... 996.0 997.0 998.0
array([ 0., 1., 2., ..., 996., 997., 998.])
- experiment_id(experiment_id)object'piControl' 'abrupt-4xCO2'
array(['piControl', 'abrupt-4xCO2'], dtype=object)
- tas(source_id, experiment_id, year)float64-0.03737 0.004069 ... nan nan
- long_name :
- Global Mean Surface Temp Anom
- units :
- K
array([[[-0.03736524, 0.00406893, 0.04455828, ..., nan, nan, nan], [ 1.07140938, 2.01418725, 2.32329552, ..., nan, nan, nan]], [[-0.16733461, -0.02822493, 0.04195457, ..., nan, nan, nan], [ 0.77630324, 1.54849902, 1.99621127, ..., nan, nan, nan]], [[ 0.14562308, 0.04408418, -0.08098555, ..., nan, nan, nan], [ 1.18374615, 2.04866999, 2.34619645, ..., nan, nan, nan]], ..., [[-0.03036853, 0.06584321, 0.08453892, ..., nan, nan, nan], [ 1.18200949, 1.89385725, 2.25692588, ..., nan, nan, nan]], [[ 0.17016837, 0.13314367, 0.10363977, ..., nan, nan, nan], [ 1.42341397, 1.86396716, 2.45714224, ..., nan, nan, nan]], [[ 0.13586615, 0.14768545, 0.04703649, ..., nan, nan, nan], [ 0.85772646, 1.80699284, 2.22705602, ..., nan, nan, nan]]]) - imbalance(source_id, experiment_id, year)float64-0.04809 0.06711 0.0311 ... nan nan
- long_name :
- Global Mean Radiative Imbalance
- units :
- W m$^{-2}$
array([[[-4.80920296e-02, 6.71083887e-02, 3.10971172e-02, ..., nan, nan, nan], [ 7.38220110e+00, 6.01442788e+00, 5.27732898e+00, ..., nan, nan, nan]], [[ 3.48665834e-01, 1.90336447e-01, -1.46944366e-01, ..., nan, nan, nan], [ 6.42770942e+00, 5.35725862e+00, 4.44059965e+00, ..., nan, nan, nan]], [[-3.80325269e-01, 1.94923686e-02, 4.78535192e-01, ..., nan, nan, nan], [ 6.74982559e+00, 5.04736326e+00, 4.93654370e+00, ..., nan, nan, nan]], ..., [[-5.40448805e-02, 8.09718600e-01, -2.21324991e-01, ..., nan, nan, nan], [ 7.20182207e+00, 5.28941954e+00, 4.27461291e+00, ..., nan, nan, nan]], [[-6.69623276e-01, -6.24708335e-03, -5.35355541e-01, ..., nan, nan, nan], [ 6.43140277e+00, 4.69336866e+00, 5.40302904e+00, ..., nan, nan, nan]], [[-3.62023320e-01, -5.56523557e-01, 1.53724282e-01, ..., nan, nan, nan], [ 7.63334280e+00, 6.72012888e+00, 5.19681795e+00, ..., nan, nan, nan]]])
Plot Timeseries¶
Here we plot the global mean surface temperature for each model:
[16]:
ds_anom.tas.plot.line(col='source_id', x='year', col_wrap=5)
[16]:
<xarray.plot.facetgrid.FacetGrid at 0x7ff9495ad090>
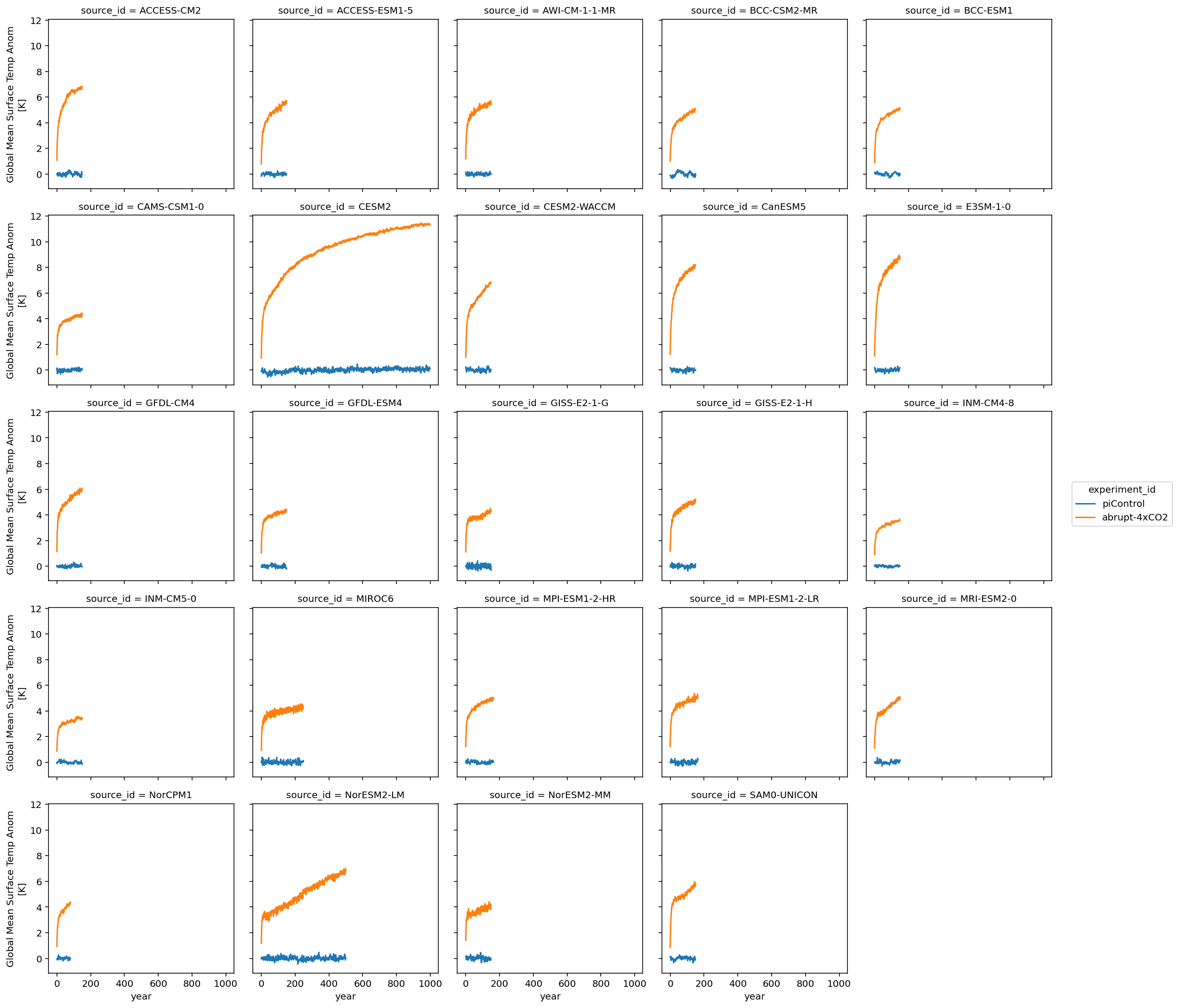
We can see that the models cover different time intervals. Let’s limit the rest of our analysis to the first 150 years.
[17]:
# limit to the gregory 150-year period
first_150_years = slice(0, 149)
ds_anom.tas.sel(year=first_150_years).plot.line(col='source_id', x='year', col_wrap=5)
[17]:
<xarray.plot.facetgrid.FacetGrid at 0x7ff93ba43a90>
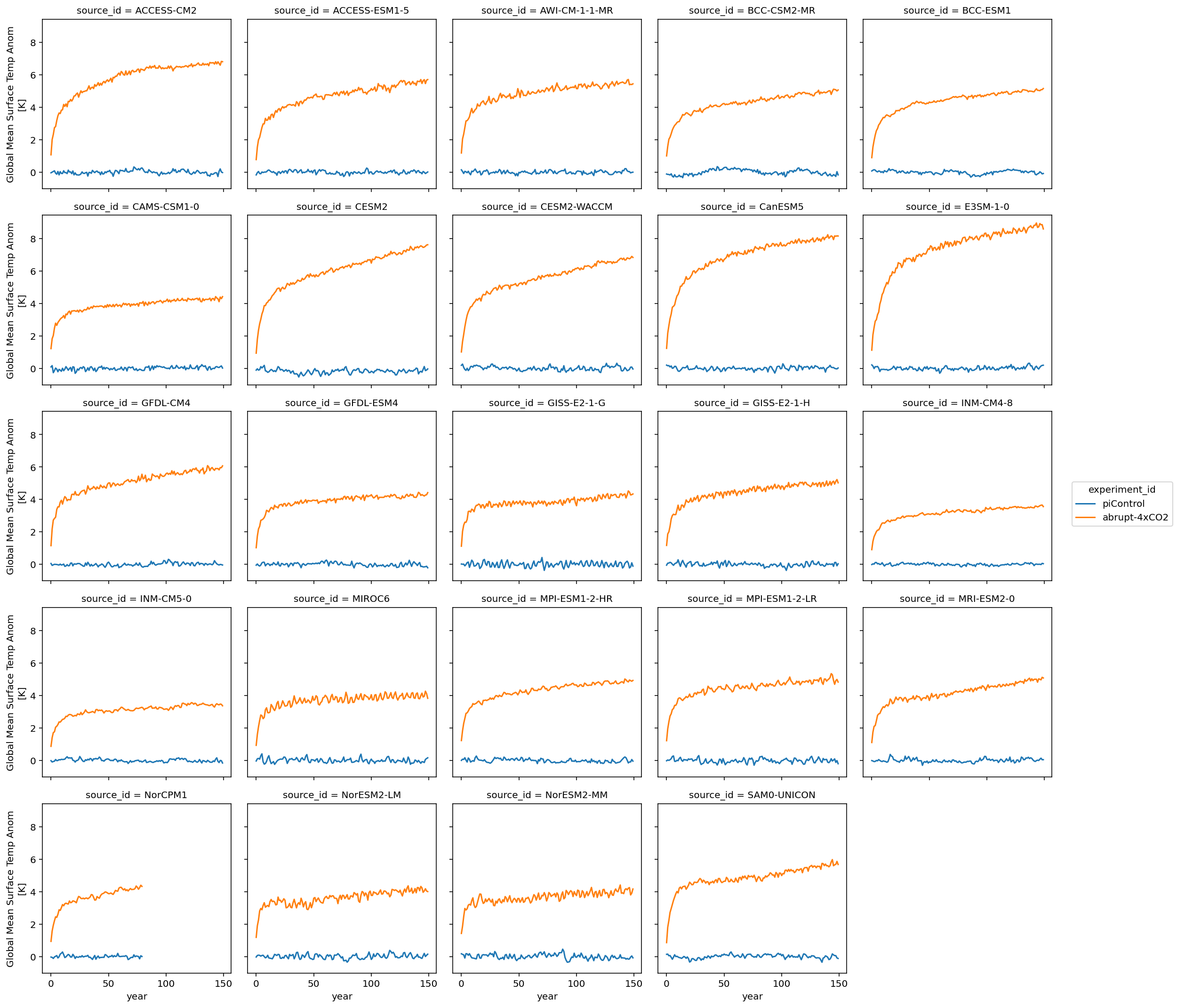
Same thing for radiative imbalance.
[18]:
ds_anom.imbalance.sel(year=first_150_years).plot.line(col='source_id', x='year', col_wrap=5)
[18]:
<xarray.plot.facetgrid.FacetGrid at 0x7ff948103b50>
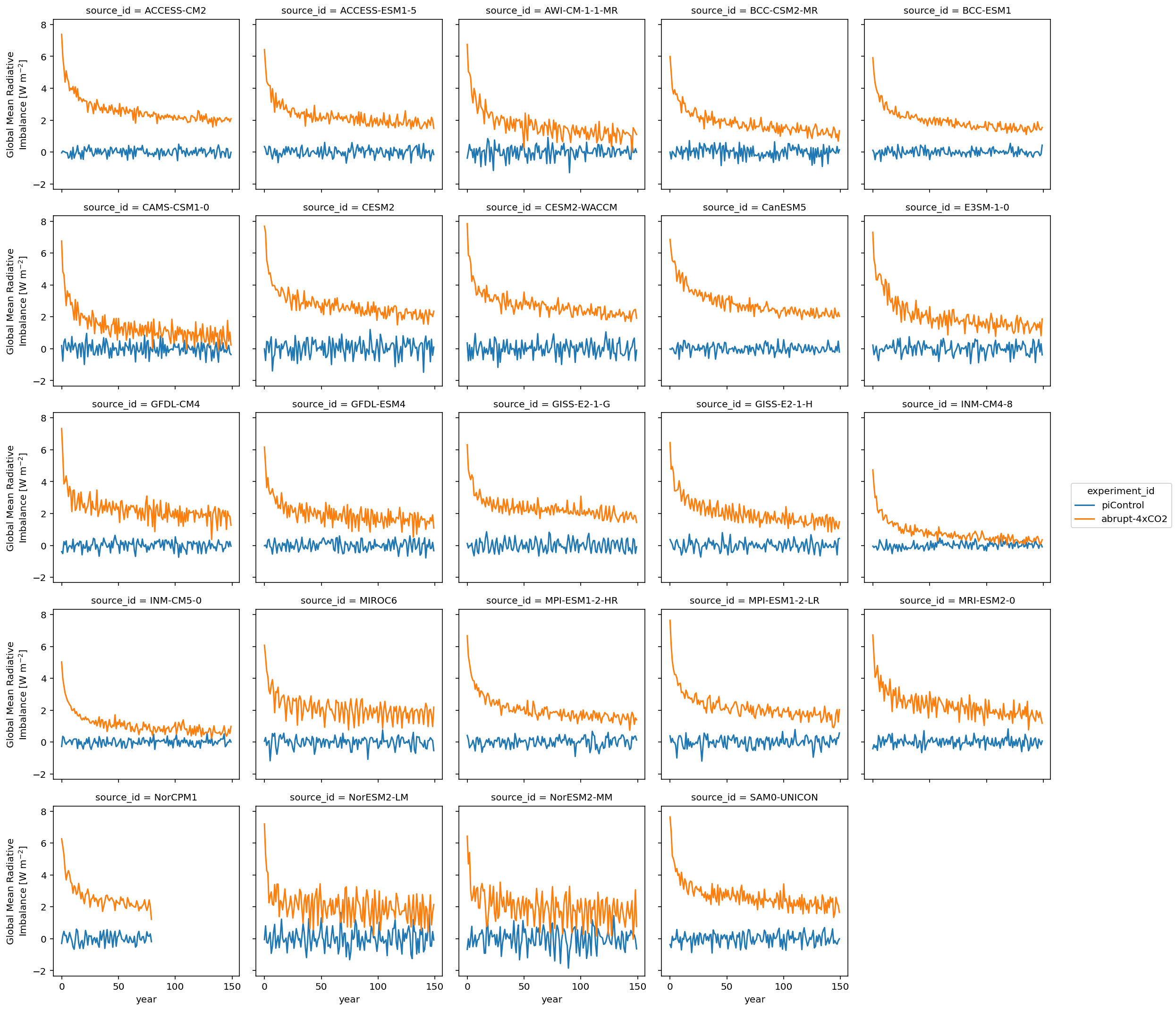
Calculate ECS¶
[19]:
ds_abrupt = ds_anom.sel(year=first_150_years, experiment_id='abrupt-4xCO2').reset_coords(drop=True)
def calc_ecs(ds):
# Some sources don't have all 150 years, drop those missing values.
a, b = np.polyfit(ds.tas.dropna("year"),
ds.imbalance.dropna("year"), 1)
ecs = -0.5 * (b/a)
return xr.DataArray(ecs)
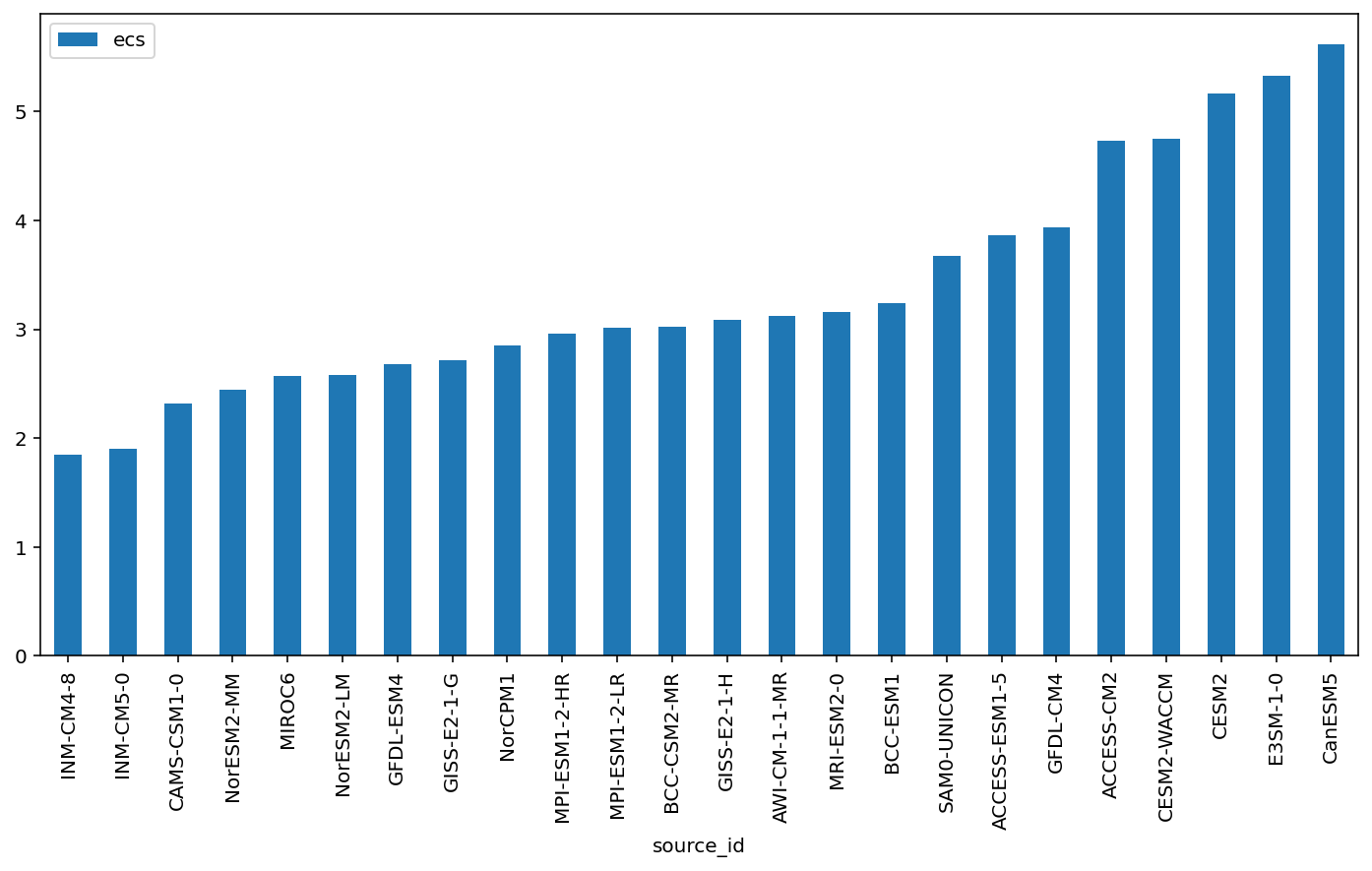
ds_abrupt['ecs'] = ds_abrupt.groupby('source_id').apply(calc_ecs)
ds_abrupt
[19]:
<xarray.Dataset>
Dimensions: (source_id: 24, year: 150)
Coordinates:
* source_id (source_id) object 'ACCESS-CM2' 'ACCESS-ESM1-5' ... 'SAM0-UNICON'
* year (year) float64 0.0 1.0 2.0 3.0 4.0 ... 146.0 147.0 148.0 149.0
Data variables:
tas (source_id, year) float64 1.071 2.014 2.323 ... 5.684 5.863 5.674
imbalance (source_id, year) float64 7.382 6.014 5.277 ... 2.254 2.088 1.652
ecs (source_id) float64 4.728 3.861 3.124 3.021 ... 2.58 2.445 3.678- source_id: 24
- year: 150
- source_id(source_id)object'ACCESS-CM2' ... 'SAM0-UNICON'
array(['ACCESS-CM2', 'ACCESS-ESM1-5', 'AWI-CM-1-1-MR', 'BCC-CSM2-MR', 'BCC-ESM1', 'CAMS-CSM1-0', 'CESM2', 'CESM2-WACCM', 'CanESM5', 'E3SM-1-0', 'GFDL-CM4', 'GFDL-ESM4', 'GISS-E2-1-G', 'GISS-E2-1-H', 'INM-CM4-8', 'INM-CM5-0', 'MIROC6', 'MPI-ESM1-2-HR', 'MPI-ESM1-2-LR', 'MRI-ESM2-0', 'NorCPM1', 'NorESM2-LM', 'NorESM2-MM', 'SAM0-UNICON'], dtype=object) - year(year)float640.0 1.0 2.0 ... 147.0 148.0 149.0
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39., 40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52., 53., 54., 55., 56., 57., 58., 59., 60., 61., 62., 63., 64., 65., 66., 67., 68., 69., 70., 71., 72., 73., 74., 75., 76., 77., 78., 79., 80., 81., 82., 83., 84., 85., 86., 87., 88., 89., 90., 91., 92., 93., 94., 95., 96., 97., 98., 99., 100., 101., 102., 103., 104., 105., 106., 107., 108., 109., 110., 111., 112., 113., 114., 115., 116., 117., 118., 119., 120., 121., 122., 123., 124., 125., 126., 127., 128., 129., 130., 131., 132., 133., 134., 135., 136., 137., 138., 139., 140., 141., 142., 143., 144., 145., 146., 147., 148., 149.])
- tas(source_id, year)float641.071 2.014 2.323 ... 5.863 5.674
- long_name :
- Global Mean Surface Temp Anom
- units :
- K
array([[1.07140938, 2.01418725, 2.32329552, ..., 6.59542693, 6.82945103, 6.8111678 ], [0.77630324, 1.54849902, 1.99621127, ..., 5.46338329, 5.67455221, 5.71011885], [1.18374615, 2.04866999, 2.34619645, ..., 5.4173639 , 5.40232712, 5.44678979], ..., [1.18200949, 1.89385725, 2.25692588, ..., 4.1791039 , 4.03828461, 4.0039116 ], [1.42341397, 1.86396716, 2.45714224, ..., 3.79755753, 3.90785916, 4.16274212], [0.85772646, 1.80699284, 2.22705602, ..., 5.68410647, 5.86317912, 5.67399347]]) - imbalance(source_id, year)float647.382 6.014 5.277 ... 2.088 1.652
- long_name :
- Global Mean Radiative Imbalance
- units :
- W m$^{-2}$
array([[7.3822011 , 6.01442788, 5.27732898, ..., 2.08403801, 1.90367848, 2.09055191], [6.42770942, 5.35725862, 4.44059965, ..., 2.17778539, 1.98275413, 1.48539794], [6.74982559, 5.04736326, 4.9365437 , ..., 1.39788496, 1.22811255, 1.10354851], ..., [7.20182207, 5.28941954, 4.27461291, ..., 0.87014436, 1.65871154, 2.14078255], [6.43140277, 4.69336866, 5.40302904, ..., 1.25489836, 3.07141649, 0.76803876], [7.6333428 , 6.72012888, 5.19681795, ..., 2.25410934, 2.08828752, 1.65183319]]) - ecs(source_id)float644.728 3.861 3.124 ... 2.445 3.678
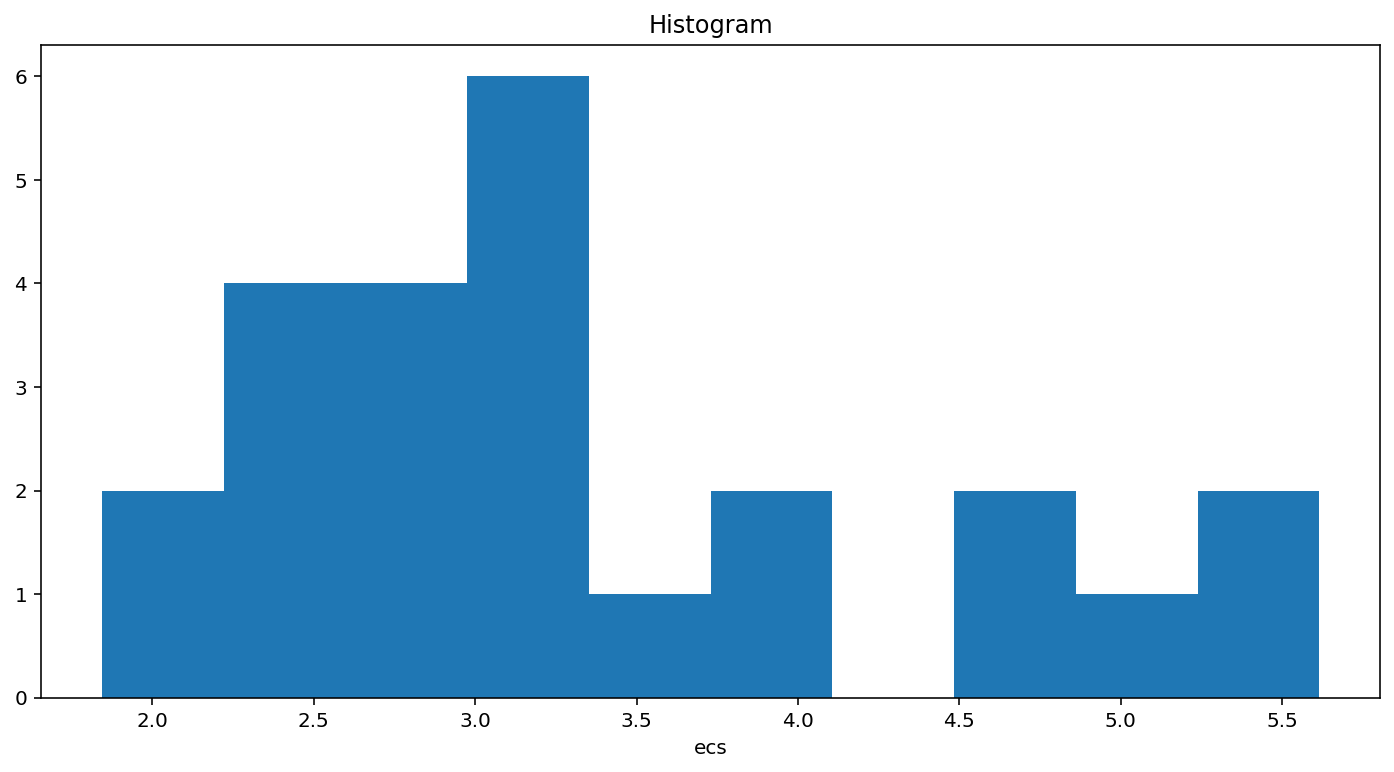
array([4.72774212, 3.86063798, 3.12447998, 3.02121386, 3.24319606, 2.31815811, 5.16811095, 4.74685881, 5.61545956, 5.32939137, 3.93408025, 2.67987955, 2.7172949 , 3.08350956, 1.84413692, 1.90151546, 2.56934772, 2.95965585, 3.00987681, 3.1617218 , 2.84818973, 2.57975106, 2.44516838, 3.6779399 ])
Reproduce a plot similar to Mark Zelinka’s:
[20]:
fg = ds_abrupt.plot.scatter(x='tas', y='imbalance', col='source_id', col_wrap=5)
def calc_and_plot_ecs(x, y, **kwargs):
x = x[~np.isnan(x)]
y = y[~np.isnan(y)]
a, b = np.polyfit(x, y, 1)
ecs = -0.5 * b/a
plt.autoscale(False)
plt.plot([0, 10], np.polyval([a, b], [0, 10]), 'k')
plt.text(4, 6, f'ECS = {ecs:3.2f}', fontdict={'weight': 'bold', 'size': 12})
plt.grid()
fg.map(calc_and_plot_ecs, 'tas', 'imbalance')
[20]:
<xarray.plot.facetgrid.FacetGrid at 0x7ff93986b050>
[21]:
ds_abrupt.ecs.plot.hist();
[21]:
(array([2., 4., 4., 6., 1., 2., 0., 2., 1., 2.]),
array([1.84413692, 2.22126918, 2.59840145, 2.97553371, 3.35266598,
3.72979824, 4.1069305 , 4.48406277, 4.86119503, 5.2383273 ,
5.61545956]),
<BarContainer object of 10 artists>)
[22]:
ds_abrupt.ecs.to_dataframe().sort_values('ecs').plot(kind='bar')
[22]:
<AxesSubplot:xlabel='source_id'>